RocketMQ
优点
- 本身支持集群架构,可以做到负载均衡,水平扩展能力
- 亿级别的消息堆积能力
- 零拷贝原理、顺序写盘、随机读
- api丰富
- 底层使用Netty NIO通信
- 消息支持重试机制、死信队列可查询
- 社区活跃、成熟、经过双十一考验
概念模型
- Producer Group:生产者组,用于生产一类消息
- Consumer Group:消费者组,用于消费一类消息
- NameSrv:用于协调Broker集群,保存消费者组的消费位置
- Broker:MQ消息服务,用于消息存储和生产消费转发
简单可以分为三大块:
- 写入前准备
- 加锁后消息写入
- 消息落盘及集群同步
Producer
一个JVM进程中,不能出现同名的ProducerGroup
消息类型
同步消息
发送后会返回是否发送成功
异步消息
消息发送成功或者失败
单向消息
消息发送是否成功不需要管,不安全的消息发送方式,性能最好
延迟消息
消息发送到broker之后,并不是一个可用状态,延迟时间达到后将可用状态置为可用,才可以被消费
事务消息
…
Consumer
注意事项:
- 一个JVM进程中,不能出现同名的ConsumerGroup
- 一个Topic可以被多个ConsumerGroup消费(rocketmq使用consumer group + queue的方式来管理消费进度,即每一个消费者组在每一个consume queue中都有独立的消费进度)
- 一个消费者组同时只能消费一个topic中的消息(broker中保存了kv形式的数据结构,类似consumer group:topic,所以consumer group消费多个topic,只按照最后一个上报给broker的topic为准)
消费模式
使用offset保存消费偏移量
集群模式
集群模式使用RemoteBrokerOffsetStore保存offset
将offset保存到broker服务上,保证消费者组集群同时只有一台机器能消费到消息
广播模式
使用LocalFileOffsetStore保存offset
将offset保存到消费者组的本地,以达到广播模式让每一个消费者组都能消费到广播的消息
消息推拉机制
PUSH消息推送模式
看似是broker主动push推送消息到客户端
实际上是客户端主动请求,broker会看是否有消息返回,如果没有则阻塞一段时间(默认5s),然后再判断是否有消息返回,没有则再次阻塞,直到达到阻塞时间的上限(默认15s),还没有消息就给客户端返回空,然后由客户端继续发送请求来请求消息,这种实现方式实际上叫做长轮训机制,由客户端不断的轮训请求broker,达到一个看似是broker推送消息的一个效果
PULL主动拉取消息模式
可以拿到topic下的多个MessageQueue
需要指定从哪个offset位置开始拉取,并且拉取做少条,所以本地需要自己维护已经消费到哪个offset了
拉取的结果有状态
- FOUND:拉取到数据
- NO_MATCHED_MSG:有消息,但是指定的条件(如指定了tag)没有消息
- NO_NEW_MSG:没有新的消息了
- OFFSET_ILLEGAL:offset不合法
消息消费
消费者组初次消费的消费起点策略
消息实际的存储结构
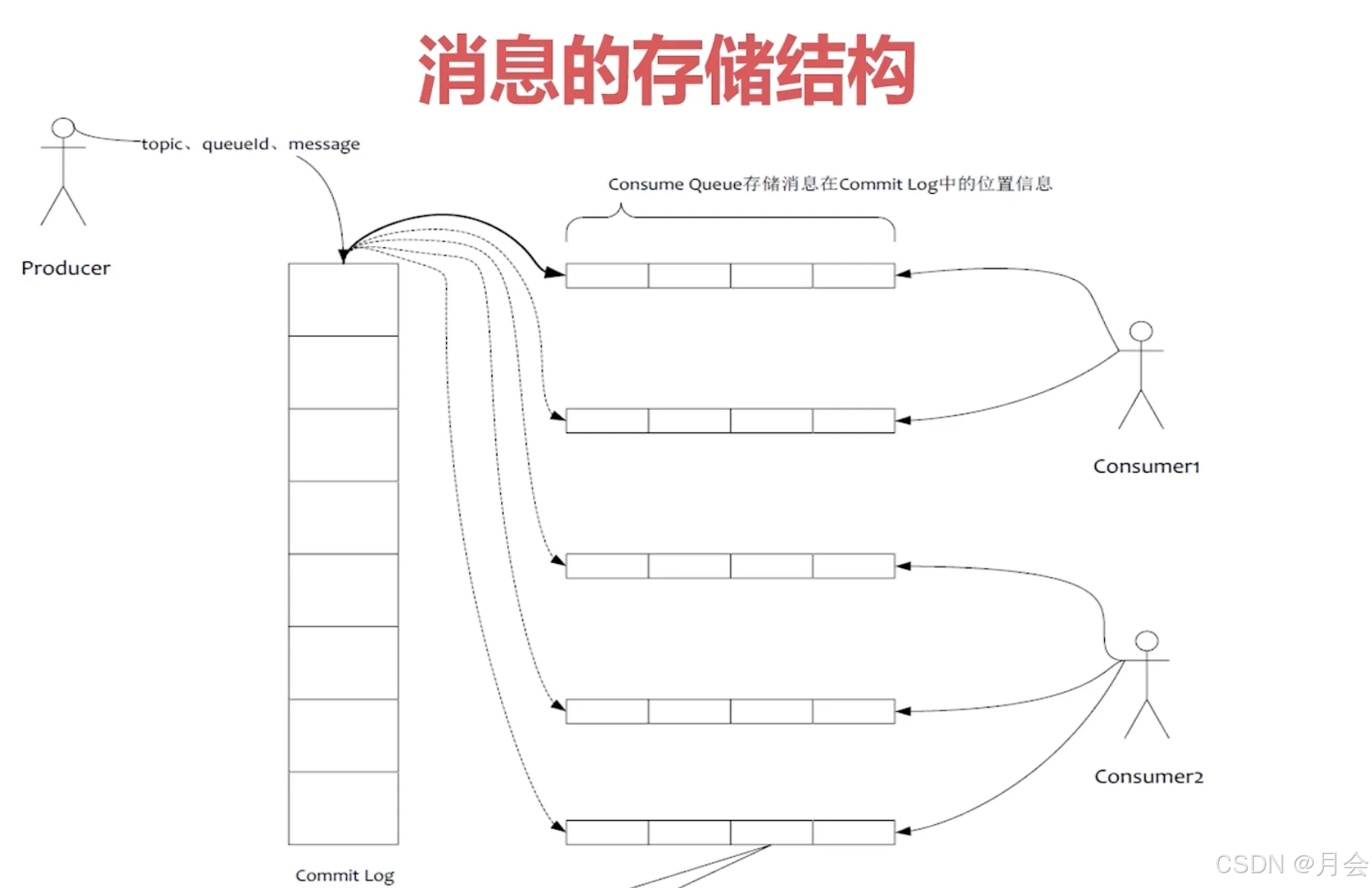
commit log(物理存储)
存储位置:$HOME/storte/commitLog
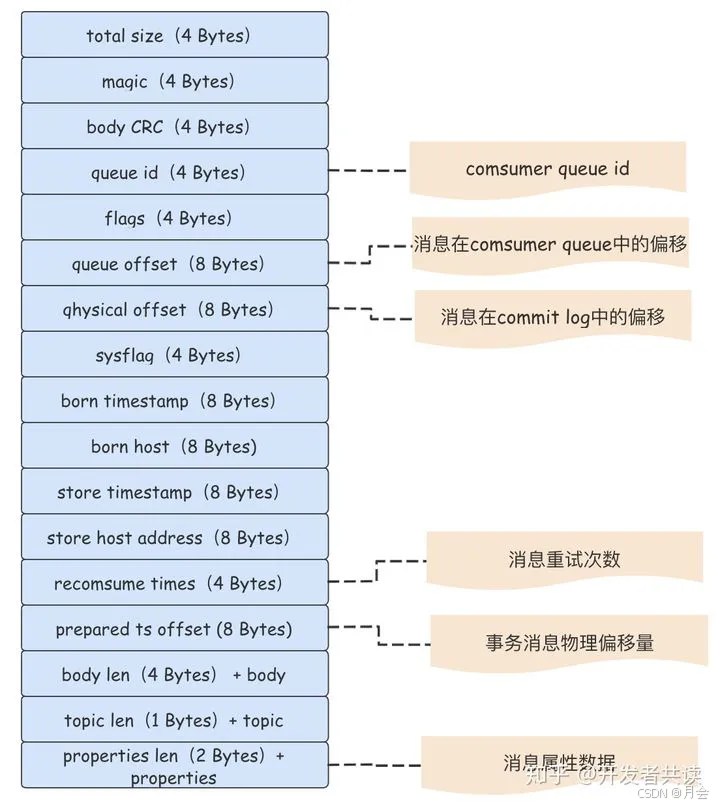
commit log是消息完整信息的实际存放位置,Producer发送的消息按照顺序写的方式写入到磁盘中,rocketmq使用混合存储,即多个topic的消息都会存储在相同的commit log中。
单个commit log文件默认大小为1GB,文件名长度为20位,文件名规则是按照字节计算的起始偏移量然后左侧补0(见图)

00000000000000000000第一个文件,物理偏移量为000000000001073741824第二个文件,物理偏移量为1G00000000002147483648第三个文件,物理偏移量为2G00000000003221225472第四个文件,物理偏移量为3G
消息的实际存放位置,commit log中保存了所有的消息的完整信息
通常情况下一个commit log文件为1GB大小,如果当前commit log还没有写满1G,但是新写一条消息会超过1G,这种情况会在commit log文件的尾部写入一个“尾部空间剩余大小”的值
每一条消息的存储内容如图
consume queue(逻辑队列)
存储位置:$HOME/store/consumequeue/{topic}/{queueId}
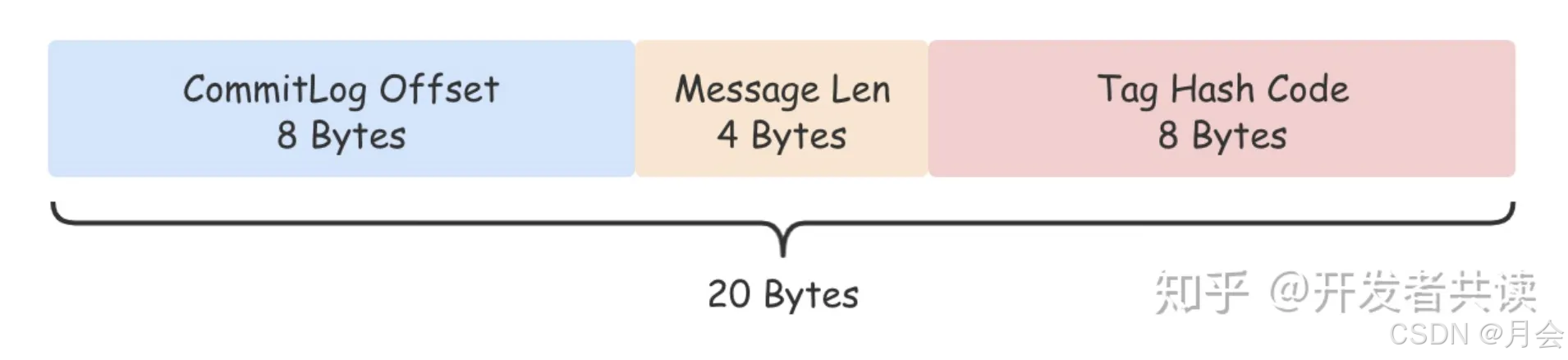
由于commit log是顺序写的,消费消息时又是按照topic来消费的,如果从commit log中去遍历寻找消息来消费效率很低,所以consume queue中保存了每一条消息在commit log中的物理偏移量,以及消息大小、tag的hash值
index file(索引文件)
index file提供了通过key(topic + msgId)或者时间区间查询消息的方式
文件名以index file创建的时间戳命名
Master - Slave主从同步机制
Master提供读写,Slave只提供读不提供写入
Broker在启动的时候会识别自己的角色(是master还是slave),如果是slave,则会启动定时任务同步元数据
- 元数据同步,使用定时任务同步(使用Netty),同步内容如下
- 主题的配置
- 消费者偏移量,即消费进度
- 同步延迟偏移量
- 同步订阅组配置信息
- commitlog同步,实时全量同步(原生Socket实现)
- 同步消息内容
- 同步所有配置
刷盘方式
RocketMQ消息存储方式:内存 + 磁盘存储,对应了两种刷盘方式
- 异步刷盘
- 同步刷盘
异步刷盘
消息写入内存后就立马返回成功,当写入到配置的内存上限时再一次性刷盘
优点:吞吐量高
缺点:有消息丢失概率
同步刷盘
消息写入内存后,刷盘完成才返回成功
集群下的消息复制
broker的master和slave之间会对消息进行复制
异步复制
master节点消息写入成功即完成,不会立马复制到slave节点上
同步复制
master中每写入一条消息就立马复制给slave节点,并且复制成功,消息才算写入完成
高可用
通过master-slave主从来实现
配置文件中通过brokerId=0为master,brokerId>0为slave
master提供读写,slave只提供读